Blog
Monitoring Docker, OpenShift and Kubernetes - Version 5.19
The main focus of this release was to implement feature requests that we received from our users and various configuration updates for the latest versions of Kubernetes, OpenShift and Docker.
(Kubernetes and OpenShift) Modifying objects streamed with Kubernetes Watch Input
Collectord can Watch and Stream any types of objects from the Kubernetes API. Both OpenShift and Kubernetes deployments have by default enabled Kubernetes Watch inputs for Pods and ResourceQuotas. And users always had the ability to add their own inputs for the types of objects they want: ConfigMaps, Deployments, and any other types of objects. But there was an issue: if you wanted to also stream Secrets to Splunk, you did not want to expose secret values. With this release we have added the ability to remove some fields from the objects, or hash their values.
If in the ClusterRole collectorforkubernetes or collectorforopenshift you add secrets under resources to give
Collectord the ability to have access to those objects, you can add another input in 004-addon.conf
1[input.kubernetes_watch::secrets]
2disabled = false
3refresh = 10m
4apiVersion = v1
5kind = Secret
6namespace =
7type = kubernetes_objects
8index =
9output =
10excludeManagedFields = true
11# hash all fields before sending them to Splunk
12modifyValues.object.data.* = hash:sha256
13# remove annotations like last-applied-configuration not to expose values by accident
14modifyValues.object.metadata.annotations.kubectl* = removeOne of the secrets that I had on my cluster was
1apiVersion: v1
2kind: Secret
3metadata:
4 name: bootstrap-token-5emitj
5 namespace: kube-system
6data:
7 auth-extra-groups: c3lzdGVtOmJvb3RzdHJhcHBlcnM6a3ViZWFkbTpkZWZhdWx0LW5vZGUtdG9rZW4=
8 expiration: MjAyMC0wOS0xM1QwNDozOToxMFo=
9 token-id: NWVtaXRq
10 token-secret: a3E0Z2lodnN6emduMXAwcg==
11 usage-bootstrap-authentication: dHJ1ZQ==
12 usage-bootstrap-signing: dHJ1ZQ==
13immutable: trueCollectord forwarded this secret to Splunk and hashed all values under data

The syntax of modifyValues. is simple, everything that goes after is a path with a simple glob pattern where * can
be in the beginning of the path property or the end. The value can be a function remove or hash:{hash_function},
the list of hash functions is the same that can be applied with annotations.
You can read more about how to Stream and Query API Objects in
- Monitoring OpenShift: Streaming Kubernetes Objects from the API Server
- Monitoring Kubernetes: Streaming Kubernetes Objects from the API Server
(OpenShift, Kubernetes) Allow overriding collectord.io annotations from Configurations
With the annotations collectord.io you can change how Collectord forwards events to Splunk HTTP Event Collector.
In version 5.12 we also introduced Cluster Level Annotations where you can define annotations for multiple Pods in
your cluster by defining matching specs (for example apply those annotations when the image name is matching regular
expression pattern).
But if you already have an annotation, for example, collectord.io/index=foo defined on Namespace, Deployment or Pod,
and if you are trying to apply this annotation from Cluster Level Configuration as collectord.io/index=bar, the one
from the objects will take priority.
With this version we introduced a force modifier that will force overriding those annotations, even if you have
them defined on the objects.
1apiVersion: "collectord.io/v1"
2kind: Configuration
3metadata:
4 name: apply-to-all-nginx
5 annotations:
6 collectord.io/index: bar
7spec:
8 kubernetes_container_image: "^nginx(:.*)?$"
9force: trueNOTE: if you have an annotation defined in the namespace as
collectord.io/logs-index=foo, it will still take priority overindex=bar, aslogs-index=foois type specific.
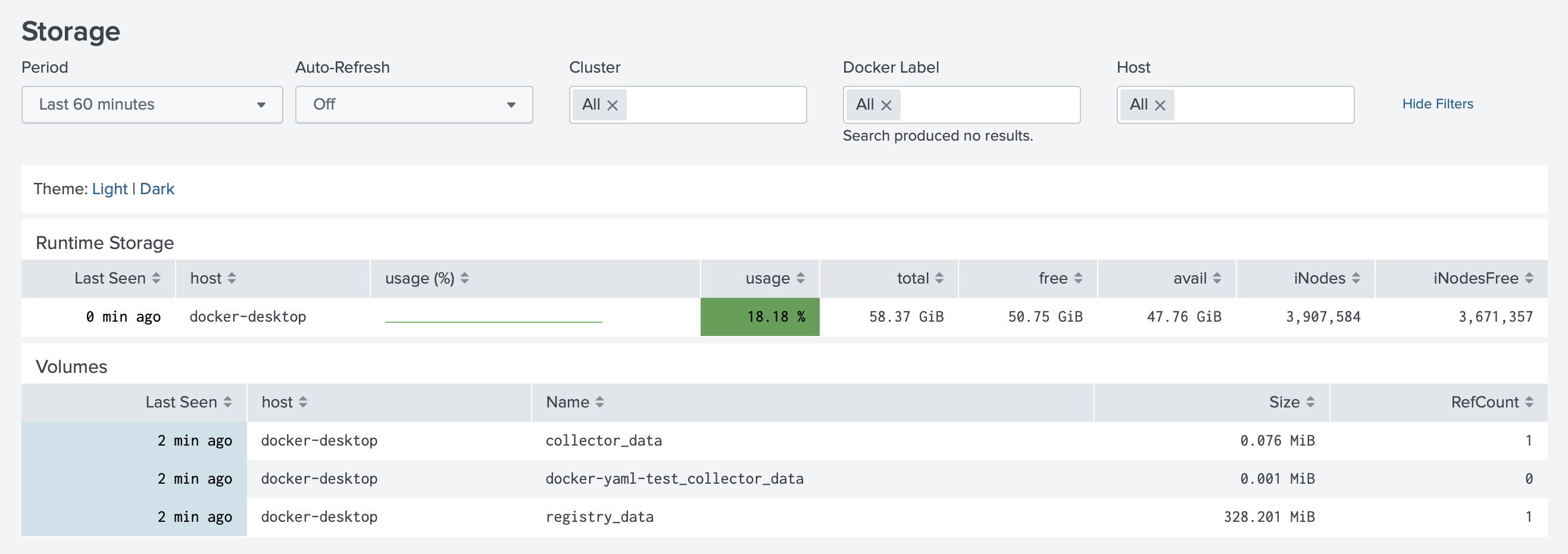
(Docker) Streaming system/df to get information about Docker Volumes
We have improved the Docker API input as well. There are some API responses that don’t return arrays, but objects
with properties containing arrays. One of them is system/df that can return information about Volumes.
By default, collectorfordocker now has input.docker_api::system enabled, that forwards information about Volumes.
Monitoring Docker application now has list of volumes under Review->Storage
(OpenShift, Kubernetes, Docker) Monitoring if node needs to be rebooted
In version 5.12 we have added first diagnostics check for the node-entropy,
in this release we have added a new one [diagnostics::node-reboot-required] that will monitor for the presence of
files under /var/run/reboot-required* and write in the logs ALARM-ON "node-reboot-required".
Applications now have an alert enabled that will notify you if some ALARMS are ON (entropy or reboot-required).
(Kubernetes, OpenShift) Improved work with Kubernetes API server, when watching Pods
Collectord was built from day one as container-native logging solution. We provide a different approach for collecting logs, where we watch first of all new created containers, and only after that monitor container logs on the disk.
When Collectord learns about a new Pod, it traverses the ownership tree to collect as much metadata as possible. That approach
worked great for a while, but with the growing number of Operators, the ownership tree can be really large. That
could cause 403 requests from Collectord to the API Server, as there could be some resources that aren’t allowed by
ClusterRole.
With this release Collectord has an API Gate that will not allow it to traverse the ownership tree with the objects it does not
have access to. Under [general.kubernetes] you just need to tell Collectord which clusterrole is used.
For OpenShift that would be clusterrole = collectorforopenshift, for Kubernetes clusterrole = collectorforkubernetes.
And if this ClusterRole allows Collectord to read clusterroles, it will read it, and use it to block any requests
to API Server, not causing any 403 requests on API Server.
Splunk output additional configurations
maximumMessageLength
You can configure maximumMessageLength to truncate messages before sending them to Splunk.
For example if you define maximumMessageLength = 256K, Collectord truncates message for all events that have length
exceeding this size, and adds a field to the event collectord_errors=truncated, allowing you to review truncated events.
requireExplicitIndex
This was a popular feature requests. Adds additional option to implement opt-out by default behavior for forwarding
logs and metrics. If requireExplicitIndex is set to true Collectord does not forward events (logs and metrics) that
do not have index explicitly configured with annotations or in the ConfigMap. By default, Collectord forwards those
events with empty index, and in case of HTTP Event Collector it uses default index set for the Token.
Links
You can find more information about other minor updates by following the links below.
Release notes
- Monitoring OpenShift - Release notes
- Monitoring Kubernetes - Release notes
- Monitoring Docker - Release notes


