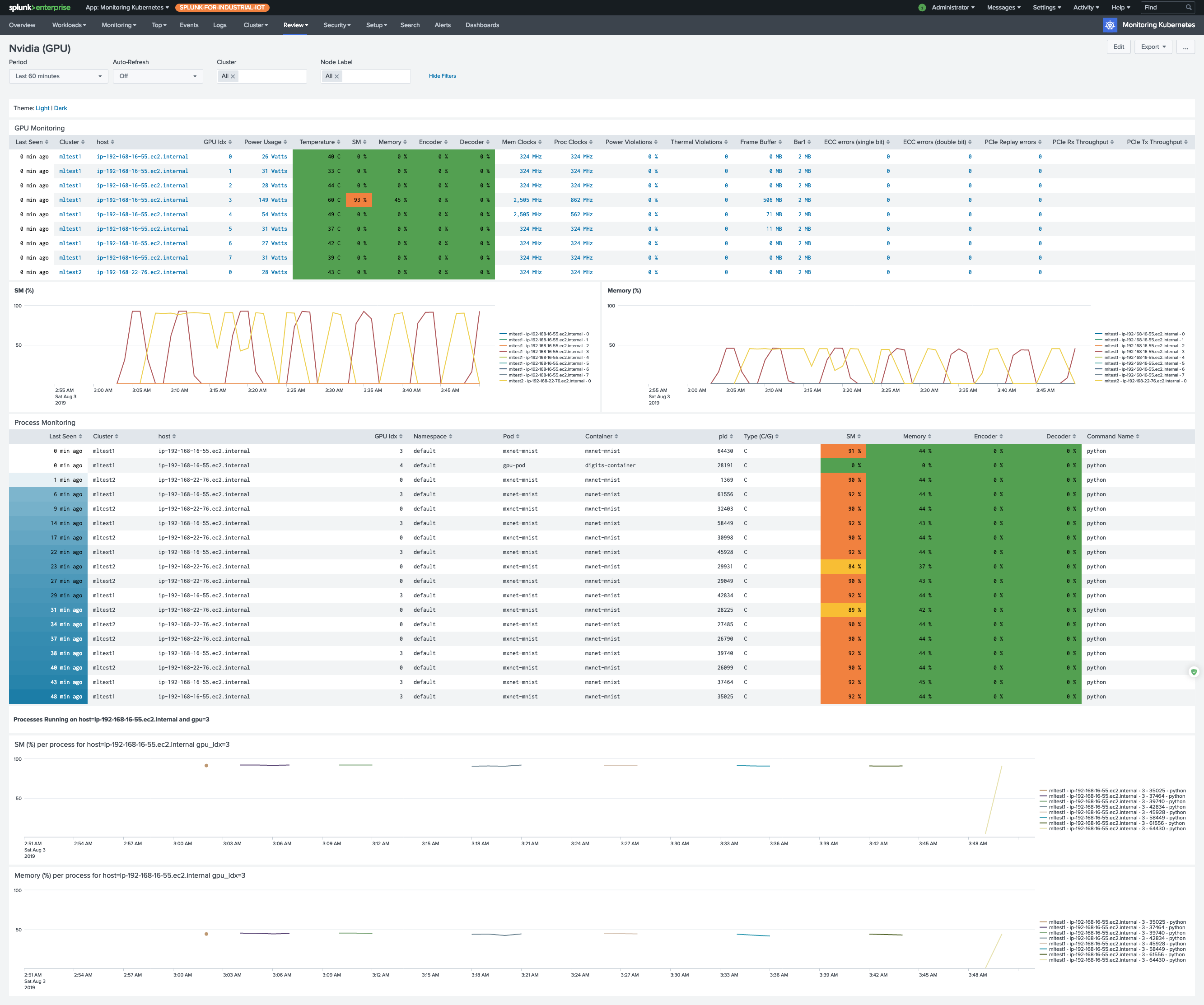
Monitoring GPU (beta)
Monitoring Nvidia GPU devices
Installing collection
Pre-requirements
If in your cluster not all nodes have GPU devices attached, label them similarly to
kubectl label nodes <gpu-node-name> hardware-type=NVIDIAGPU
The DaemonSet that we use below rely on this label.
Nvidia-SMI DaemonSet
We use nvidia-smi tool to collect metrics from the GPU devices. You can find documentation of this tool at
https://developer.nvidia.com/nvidia-system-management-interface.
We also use set of annotations to conver the output from this tool into easy parsable CSV format, which helps ut to
configure fields extraction with Splunk.
Create a file nvidia-smi.yaml and save it with the following content.
apiVersion: apps/v1 kind: DaemonSet metadata: name: collectorforkubernetes-nvidia-smi namespace: collectorforkubernetes labels: app: collectorforkubernetes-nvidia-smi spec: updateStrategy: type: RollingUpdate selector: matchLabels: daemon: collectorforkubernetes-nvidia-smi template: metadata: name: collectorforkubernetes-nvidia-smi labels: daemon: collectorforkubernetes-nvidia-smi annotations: collectord.io/logs-joinpartial: 'false' collectord.io/logs-joinmultiline: 'false' # remove headers collectord.io/logs-replace.1-search: '^#.*$' collectord.io/logs-replace.1-val: '' # trim spaces from both sides collectord.io/logs-replace.2-search: '(^\s+)|(\s+$)' collectord.io/logs-replace.2-val: '' # make a CSV from console presented line collectord.io/logs-replace.3-search: '\s+' collectord.io/logs-replace.3-val: ',' # empty values '-' replace with empty values collectord.io/logs-replace.4-search: '-' collectord.io/logs-replace.4-val: '' # nothing to report from pmon - just ignore the line collectord.io/pmon--logs-replace.0-search: '^\s+\d+(\s+-)+\s*$' collectord.io/pmon--logs-replace.0-val: '' # set log source types collectord.io/pmon--logs-type: kubernetes_gpu_nvidia_pmon collectord.io/dmon--logs-type: kubernetes_gpu_nvidia_dmon spec: # Make sure to attach matching label to the GPU node # $ kubectl label nodes <gpu-node-name> hardware-type=NVIDIAGPU nodeSelector: hardware-type: NVIDIAGPU hostPID: true containers: - name: pmon image: nvidia/cuda:latest args: - "bash" - "-c" - "while true; do nvidia-smi --list-gpus | cut -d':' -f 3 | cut -c2-41 | xargs -L4 echo | sed 's/ /,/g' | xargs -I {} bash -c 'nvidia-smi pmon -s um --count 1 --id {}'; sleep 30 ;done" - name: dmon image: nvidia/cuda:latest args: - "bash" - "-c" - "while true; do nvidia-smi --list-gpus | cut -d':' -f 3 | cut -c2-41 | xargs -L4 echo | sed 's/ /,/g' | xargs -I {} bash -c 'nvidia-smi dmon -s pucvmet --count 1 --id {}'; sleep 30 ;done"
Apply this DaemonSet to your cluster with
kubectl apply -f nvidia-smi.yaml
Within version 5.11 you should see the data within the dashboard.