Blog
Monitoring Kubernetes and OpenShift - Monitoring GPU
If you are using NVIDIA GPU devices for your workloads, including machine learning (ML), high performance computing (HPC), financial analytics, and video transcoding, you want to be able to monitor how efficiently you are using these devices.
We provide a solution, based on the nvidia-smi tool, that will allow you to monitor GPU devices attached to
your Kubernetes and OpenShift nodes, to review GPU/Memory utilization, Power consumption and more.
Currently it is in beta mode, and you will need to add the required dashboards to the configurations manually. In future versions we will include these dashboards as part of our application.
Please review the documentation on installation
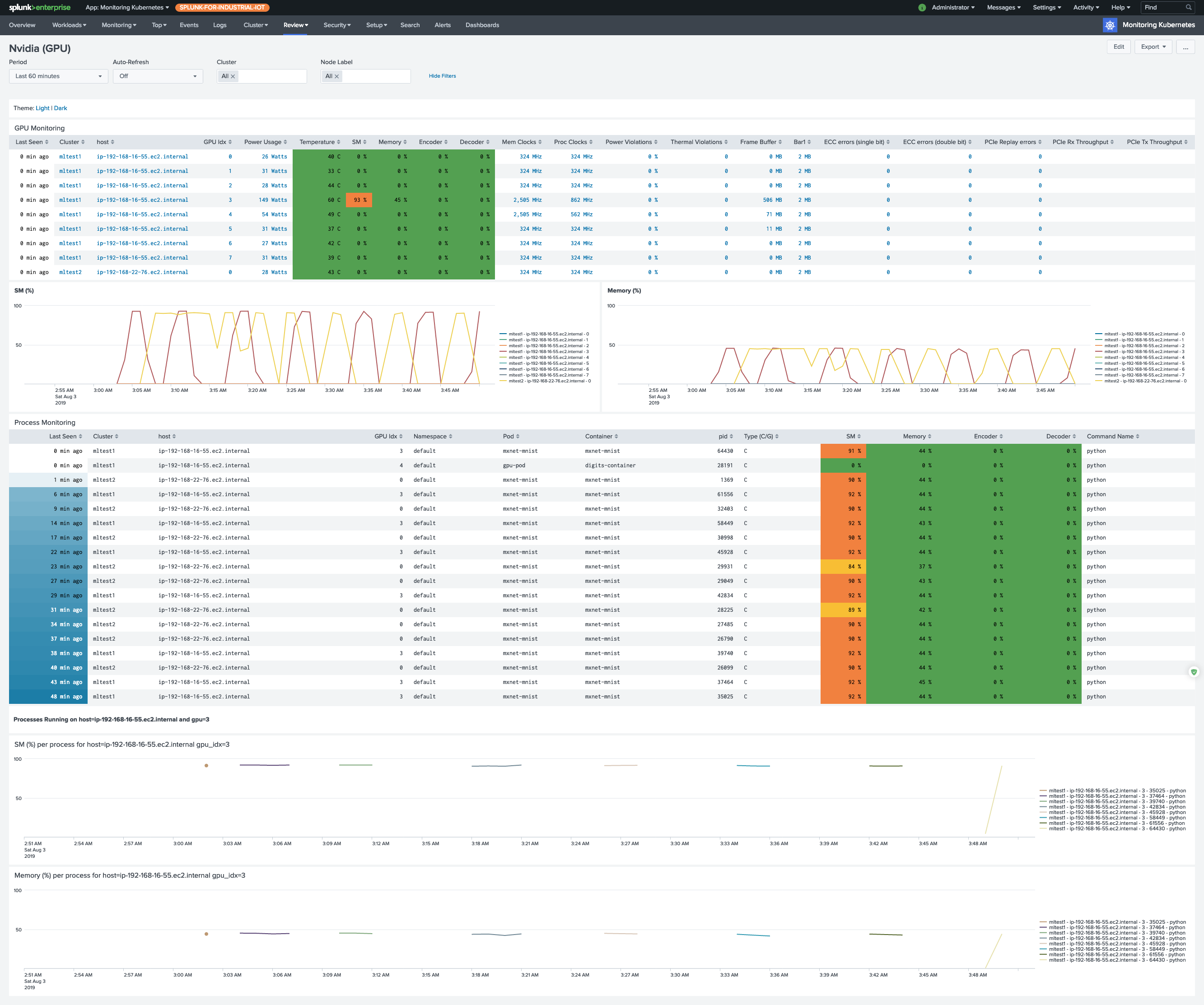
We are using the nvidia-smi tool to collect the data, which allows us to install the collection part on any Kubernetes or
OpenShift version. The official NVIDIA monitoring tool relies on Kubernetes 1.13+,
which is a significant limitation, considering that you can’t run it on the most popular OpenShift version 3.11 (which is based on Kubernetes 1.11). If you prefer to use
NVIDIA/gpu-monitoring-tools you can easily use our Prometheus annotations
to collect these metrics and forward them to Splunk.


